
Introducción
Bienvenido a tu guía rápida rápida sobre “Cómo convertirte en un experto en análisis estadístico con R”, la última guía rápida que necesitarás para empezar el poderoso camino a convertirte en un experto en análisis estadístico utilizando el lenguaje de programación R. Y es que no importa si eres un investigador, científico de datos o analista, o estudiante de pregrado, esta guía te proporcionará el conocimiento y las habilidades necesarias para analizar datos con confianza, extraer conocimientos significativos y tomar decisiones informadas.
A lo largo de esta guía, cubriremos una amplia gama de temas, desde la configuración de su entorno R y la manipulación básica de datos, hasta técnicas estadísticas avanzadas y aprendizaje automático. Al final de este viaje, podrá abordar tareas complejas de análisis de datos, visualizar sus resultados de manera efectiva y presentar sus hallazgos de manera convincente.
Ya sea que sea nuevo en la programación o tenga algo de experiencia, esta guía le brindará instrucciones paso a paso, ejemplos prácticos y ejercicios para garantizar que comprenda cada concepto a fondo. Entonces, profundicemos y comencemos su viaje para convertirse en un experto en análisis estadístico con R.

Contenidos
- Configurando su entorno R
- Instalación de R y RStudio
- Entendiendo la interfaz de R
- Gestión de paquetes
2. Manipulación de datos con dplyr
- Filtrar y seleccionar datos
- Organizar y cambiar el nombre de variables
- Resumiendo datos
3. Visualización de datos con ggplot2
- Creación de diagramas de dispersión, gráficos de barras e histogramas
- Personalización de visualizaciones
- Agregar capas y temas
- Resumiendo datos
4. Estadística Descriptiva y Análisis Exploratorio de Datos (EDA)
- Calcular la tendencia central y la dispersión
- Visualización de distribuciones de datos
- Descubriendo relaciones con EDA
5. Fundamentos estadísticos
- Distribuciones de probabilidad en R
- Técnicas de muestreo y aleatoriedad
- Teorema del límite central y ley de los grandes números
6. Evaluación de la hipótesis
- Formular hipótesis
- Pruebas t y valores p
- Pruebas ANOVA y Chi-cuadrado
7. Análisis de regresión
- Modelado de regresión lineal
- Diagnóstico y supuestos del modelo
- Regresión múltiple e interacciones
8. Informar y reportar resultados
- Crear informes con R Markdown
- Exportar gráficos y datos
- Colaboración con el control de versiones
9. Buenas prácticas de análisis de datos
- Primero, planifique y, segundo, practique un análisis de datos eficaz
- Participe en la comunidad de usuarios de R
10. Nunca deje de aprender que R sigue creciendo
- Siga aprendiendo aprovechando los cursos en línea y libros gratuitos
1. Configurando tu entorno R
Instalación de R y RStudio
Antes de comenzar nuestro viaje estadístico, debe tener R y RStudio instalados en su computadora. R es un potente lenguaje de programación para informática estadística, mientras que RStudio es un entorno de desarrollo integrado (IDE) que hace que trabajar con R sea más fácil de usar.
Instale R: Visite el sitio web de R Project y descargue la última versión de R para su sistema operativo. Siga las instrucciones de instalación proporcionadas.
LUEGO, Instale RStudio: Vaya a la página de descarga de RStudio y elija la versión adecuada de RStudio Desktop para su sistema. Instálelo siguiendo las instrucciones proporcionadas.
Entendiendo la interfaz de R
Cuando abres RStudio, verás cuatro paneles:
- Editor de secuencias de comandos: aquí es donde escribe y edita su código R. Cree un nuevo script haciendo clic en Archivo > Nuevo archivo > R Script.
- Consola: aquí es donde se ejecuta su código R. Puede escribir comandos directamente aquí o ejecutar código desde su secuencia de comandos seleccionando las líneas y haciendo clic en Ejecutar.
- Entorno/Historial: este panel muestra sus variables y sus valores. También muestra su historial de comandos.
- Archivos/Trazados/Paquetes/Ayuda: este panel le ayuda a administrar sus archivos, ver trazados, instalar y cargar paquetes y acceder a la documentación.
Gestión de paquetes
El poder de R proviene de sus paquetes: colecciones de funciones, datos y documentación. Para instalar y cargar un paquete, utilice los siguientes comandos:
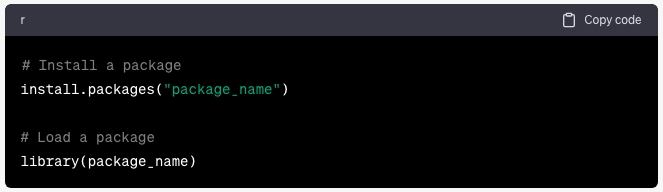
install.packages(“package_name”)
# Load a package
library(package_name)
Por ejemplo, para instalar y cargar el paquete dplyr para manipulación de datos:

library(dplyr)
Recuerda cargar los paquetes necesarios al inicio de tu script para acceder a sus funciones.
2. Manipulación de datos con dplyr
Filtrar y seleccionar datos
El paquete dplyr proporciona funciones intuitivas para manipular marcos de datos. Para filtrar filas según condiciones y seleccionar columnas específicas, use filter() y select():
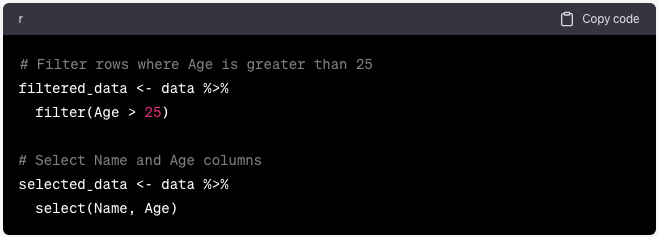
filter(Age > 25)
selected_data <- data %>%
select(Name, Age)
Organizar y cambiar el nombre de variables
Puede organizar filas por variables y cambiar el nombre de las columnas usando arrange() y cambiar rename():

arranged_data <- data %>%
arrange(desc(Age))
# Rename Age column to Years
renamed_data <- data %>%
rename(Years = Age)
Resumiendo datos
Utilice summarize() para calcular estadísticas resumidas:
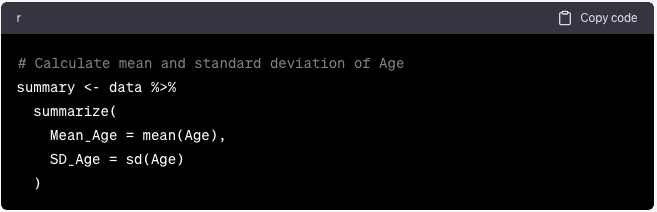
summarize(
Mean_Age = mean(Age),
SD_Age = sd(Age)
)
Estos son sólo algunos ejemplos de lo que puede lograr con dplyr. Sus funciones están diseñadas para agilizar sus tareas de manipulación de datos, permitiéndole concentrarse en el análisis.
3. Visualización de datos con ggplot2
Creación de diagramas de dispersión (Scatter Plots), gráficos de barras (Bar Charts) e histogramas (Histograms)
El paquete ggplot2 es una herramienta versátil para crear visualizaciones. A continuación se explica cómo crear diagramas de dispersión, gráficos de barras e histogramas básicos:
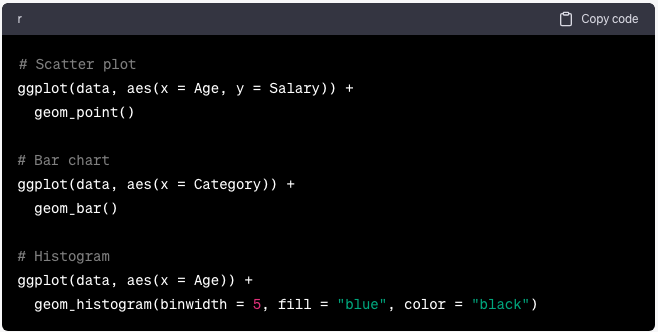
ggplot(data, aes(x = Age, y = Salary)) +
geom_point()
# Bar chart
ggplot(data, aes(x = Category)) +
geom_bar()
# Histrogram
ggplot(data, aes(x = Age)) +
geom_histogram(binwidth = 5, fill = “blue”, color = “black”)
Personalizando los gráficos
Puedes personalizar casi todos los aspectos de tu trama usando funciones adicionales de ggplot2. Por ejemplo:
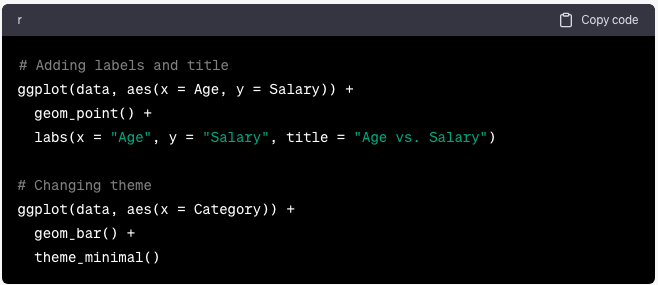
ggplot(data, aes(x = Age, y = Salary)) +
geom_point() +
labs(x = “Age”, y = “Salary”, title = “Age vs. Salary”)+
# Changing theme
ggplot(data, aes(x = Category)) +
geom_bar() +
theme_minimal()
Agregar más capas y cambiando el tema del gráfico
ggplot2 se basa en el concepto de agregar capas a un gráfico. Esto le permite crear visualizaciones complejas:
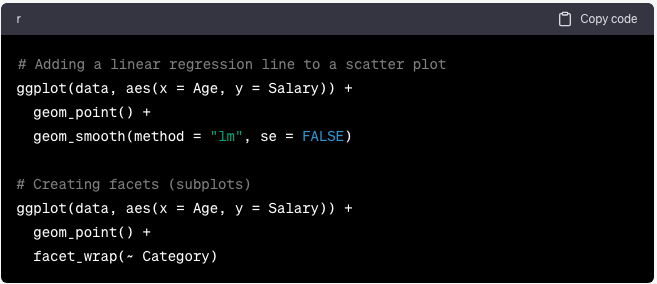
ggplot(data, aes(x = Age, y = Salary)) +
geom_point() +
geom_smooth(method = “lm”, se = FALSE)
# Creating facets (subplots)
ggplot(data, aes(x = Age, y = Salary)) +
geom_point() +
facet_wrap(~ Category)
# Creating facets (subplots)
ggplot(data, aes(x = Age, y = Salary)) +
geom_point() +
facet_wrap(~ Category)
4. Estadística Descriptiva y Análisis Exploratorio de Datos (EDA)
Medidas de tendencia central y medidas de dispersión
Utilice las funciones integradas de R para calcular la tendencia central (media, mediana) y la dispersión (rango, desviación estándar):
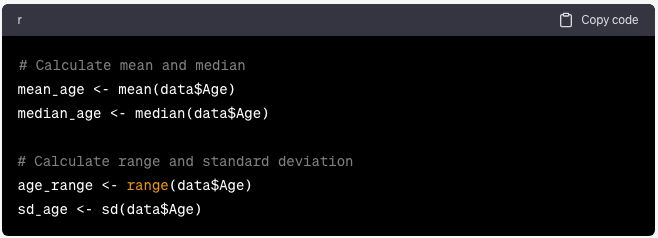
mean_age <- mean(data$Age)
median_age <- median(data$Age)
# Calculate range and standard deviation
age_range <- range(data$Age)
sd_age <- sd(data$Age)
Visualización de distribuciones de datos
Los histogramas y los gráficos de densidad brindan información sobre las distribuciones de datos:

hist(data$Age, breaks = 10, col = “skyblue”, border = “black”,
xlab = “Age”, ylab = “Frequency”, main = “Age Distribution”)m
#Density plot
density_plot <- ggplot(data, aes(x = Age)) +
geom_density(fill = “blue”, alpha = 0.5) +
labs(x = “Age”, y = “Density”)
Descubriendo relaciones con EDA
Utilice diagramas de dispersión y análisis de correlación para explorar las relaciones entre variables:
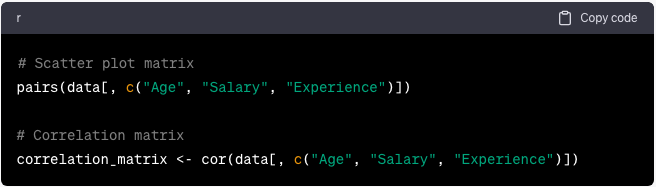
pairs(data[, c(“Age”, “Salary”, “Experience”)])
# Correlation matrix
correlation_matrix <- cor(data[, c(“Age”, “Salary”, “Experience”)])
5. Fundamentos de estadística
Distribuciones de probabilidad en R
R ofrece funciones para trabajar con varias distribuciones de probabilidad:
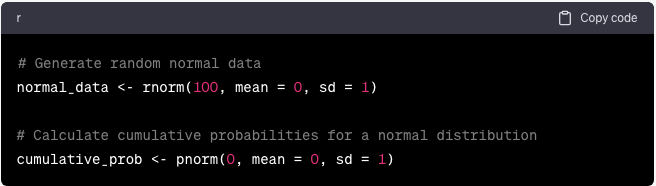
normal_data <- rnorm(100, mean = 0, sd = 1)
# Calculate cumulative probabilities for a normal distribution
cumulative_prob <- pnorm(0, mean = 0, sd = 1)
Técnicas de muestreo y aleatoriedad
Comprender los métodos de muestreo es crucial en estadística:
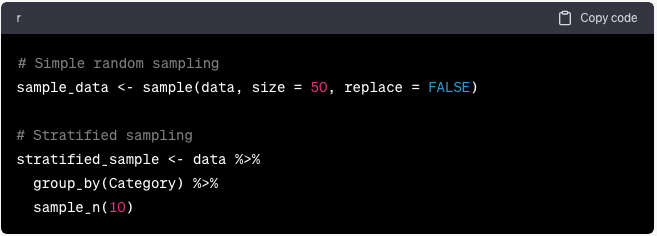
sample_data <- sample(data, size = 50, replace = FALSE)
# Stratified sampling
stratified_sample <- data %>%
group_by(Category) %>%
sample_n(10)
Teorema del límite central y ley de los grandes números
El teorema del límite central establece que la distribución de las medias muestrales se aproxima a una distribución normal:
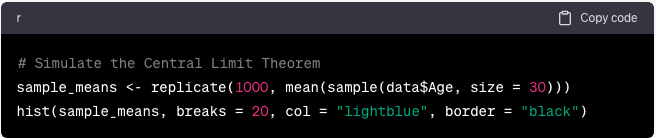
sample_means <- replicate(1000, mean(sample(data$Age, size = 30)))
hist(sample_means, breaks = 20, col = “lightblue”, border = “black”)
6. Prueba de hipótesis
Formular hipótesis
Comprender los componentes de la prueba de hipótesis:
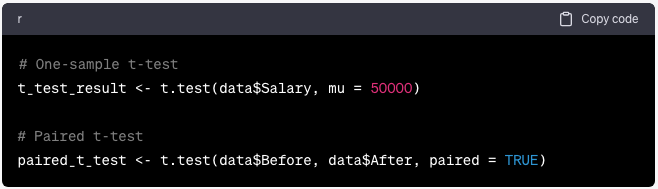
t_test_result <- t.test(data$Salary, mu = 50000)
# Paired t-test
paired_t_test <- t.test(data$Before, data$After, paired = TRUE)
Pruebas t y valores p
Interprete los resultados de la prueba t y los valores p:
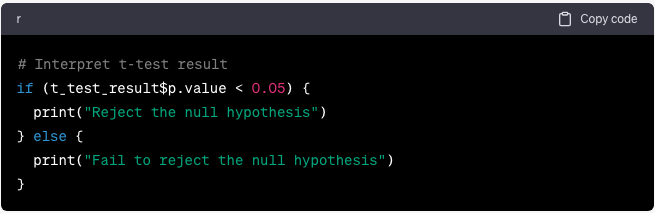
if (t_test_result$p.value < 0.05) {
print(“Reject the null hypothesis”)
} else {
print(“Fail to reject the null hypothesis”)
}
Pruebas ANOVA y Chi-cuadrado
Realice pruebas ANOVA y Chi-Cuadrado para comparaciones de grupos:
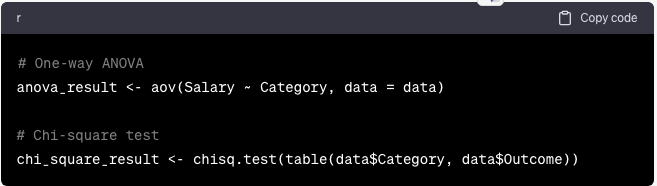
anova_result <- aov(Salary ~ Category, data = data)
# Chi-square test
chi_square_result <- chisq.test(table(data$Category, data$Outcome))
7. Análisis de regresión
Modelado de regresión lineal
Ajustar e interpretar modelos de regresión lineal:

lm_model <- lm(Salary ~ Age + Experience, data = data)
# Print model summary
summary(lm_model)
Diagnóstico y supuestos del modelo
Verifique las suposiciones del modelo y realice diagnósticos:
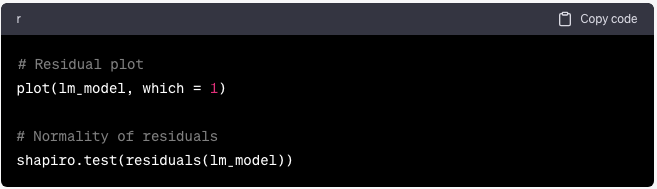
plot(lm_model, which = 1)
# Normality of residuals
shapiro.test(residuals(lm_model))
Regresión múltiple e interacciones
Amplíe el análisis de regresión a múltiples predictores e interacciones:

multi_lm_model <- lm(Salary ~ Age + Experience + Category, data = data)
# Include interaction term
interaction_model <- lm(Salary ~ Age * Experience, data = data)
8. Informe y comparta sus resultados
Crear informes con R Markdown
Genere informes reproducibles utilizando R Markdown:
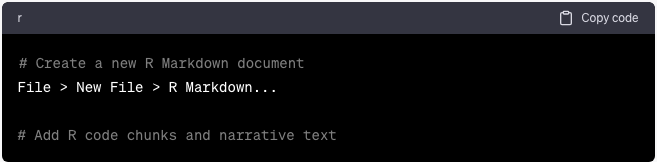
File > New File > R Markdown…
# Add R code chunks and narrative text
Exportar gráficos y tablas
Guarde sus visualizaciones y bases de datos para compartir:
ggsave(“plot.png”, plot = your_plot, width = 6, height = 4)
# Export data to a CSV file
write.csv(your_data, “data.csv”, row.names = FALSE)
Colaboración con el control de versiones
Utilice herramientas de control de versiones como Git para colaborar y administrar su código:
git init
# Add your files to the repository
git add
# Commit changes
git commit -m “Initial commit”
Buenas prácticas de análisis de datos
- Primero, planifique y, segundo, practique un análisis de datos eficaz:
Definir claramente las preguntas y objetivos de la investigación.
Limpie y preprocese los datos antes del análisis.
Documente su código y proceso de análisis.
Validar y evaluar críticamente los resultados.
- Participe de la comunidad R para aprender, compartir y crecer:
Únase a foros en línea como Stack Overflow y RStudio Community.
Asista a conferencias y reuniones de R.
Contribuir a paquetes y proyectos de R.
Explorando más recursos de aprendizaje
10. Nunca deje de aprender que R sigue creciendo
Siga aprendiendo aprovechando los cursos en línea y libros gratuitos
Aproveche los cursos online en plataformas como Coursera, edX y DataCamp.
Practique con los códigos de los libros sobre técnicas estadísticas avanzadas en R.
Lea los artículos de investigación y revistas que utilizan R como software de análisis estadístico en su campo de interés.
Desarolle sus habilidades de análiisis con proyectos y desafíos del mundo real
Analice conjuntos de datos abiertos en plataformas como Kaggle.
Participe en los concursos de análisis de datos.
Pero sobrotodo investigue y publique para demostrar tu experiencia.
Conclusión
¡Felicidades! Ha completado esta guía rápida sobre cómo convertirse en un experto el análisis estadístico con R. Si sigue estos pasos, practica constantemente y aplica sus habilidades a escenarios del mundo real, continuará creciendo como un experto en análisis estadístico con R. El cielo de la ciencia es el límite.
Y si quiere convertirse en un experto de la mano de instructor profesional no se pierda la oportunidad de hacerlo en el curso “Análisis Estadístico con R”, el único curso de R que ha validado sus contenidos y publicado su propio libro de texto!!!”

NO te lo pierdas! El curso de Análisis Estadístico con R arranca este 29 de agosto y si bien la preventa acabó el 22 tenemos vigente la campaña de “inscribete de a 2”!

Saludos cordiales,
Antonio M. Quispe, MD, PhD
@drantonioquispe